Fairness auditing
for healthcare AI
A model that looks strong in aggregate may perform substantially worse for certain populations — and those gaps are invisible without deliberate measurement.
Point it at your model's predictions and get two tailored outputs: a full 15–20 page technical report for your data scientists, and a streamlined 3–5 page governance summary for your committee. One run, two audiences, everything needed for deployment approval.
Capabilities
Clinical AI fairness metrics
through governance sign-off
Two Personas, One Run
Call audit.run() once, get two tailored outputs: a 15–20 page technical report (all metrics, bootstrap CIs, every figure) for data scientists, and a streamlined 3–5 page governance summary for committees — same data, right level of detail for each audience.
Discrimination, Calibration & Clinical Utility
AUROC, calibration curves, Brier score, DCA, and classification metrics, all with bootstrap confidence intervals. The full clinical validation stack in one call.
Subgroup Fairness Analysis
Auto-detects race, sex, insurance, age, and language columns via suggest_attributes(). Computes equalized odds, demographic parity, equal opportunity, predictive parity, and calibration per subgroup.
Plain-Language Explanations
Every metric and visualization includes clear explanations of what it means and why it matters — written for governance committees, not statisticians. Active voice, defined jargon, concrete examples.
Multiple Export Formats
HTML, PDF (via Playwright), PowerPoint decks, PNG bundles, JSON, structured model cards, responsible AI checklists, and reproducibility bundles — everything IRB, ethics boards, and journals need.
Publication-Ready Visualizations
WCAG 2.1 AA compliant, colorblind-safe Okabe-Ito palette, minimum 14px fonts. The same figures go into the data scientist report and the boardroom deck.
HIPAA-Friendly Local Processing
All computation runs locally. No cloud dependencies, no data leaves your machine. Air-gap compatible — point it at a CSV or Parquet file and get your audit.
4-Step Streamlit Dashboard
Upload predictions → Analyze fairness → Review governance summary → Export. No code required. Or use the CLI for scripted pipelines and CI/CD automation.
Quick Start
Up and running in minutes
pip install faircareFor PDF & PowerPoint exports (governance reports, committee decks):
pip install "faircare[export]"from faircareai import FairCareAudit, FairnessConfig, FairnessMetric
# Point at your model's predictions (CSV, Parquet, Pandas, or Polars)
audit = FairCareAudit(
data="predictions.parquet",
pred_col="risk_score",
target_col="readmit_30d",
)
# Auto-detect demographic columns (race, sex, insurance, language…)
audit.suggest_attributes()
audit.accept_suggested_attributes([1, 2, 3])
audit.config = FairnessConfig(
model_name="Readmission Risk Model v2",
primary_fairness_metric=FairnessMetric.EQUALIZED_ODDS,
fairness_justification=(
"Model triggers intervention; equal TPR/FPR "
"ensures equitable access to care management."
),
)
results = audit.run()
# Data scientist persona — full technical report (15–20 pages)
results.to_html("technical_report.html")
results.to_pdf("technical_report.pdf") # pip install "faircare[export]"
# Governance persona — streamlined summary (3–5 pages)
results.to_governance_pdf("governance.pdf")
results.to_pptx("committee_deck.pptx") # pip install "faircare[export]"See It In Action
One run. Two audiences.
The same audit produces a full technical report and a governance summary — each tailored to its audience.
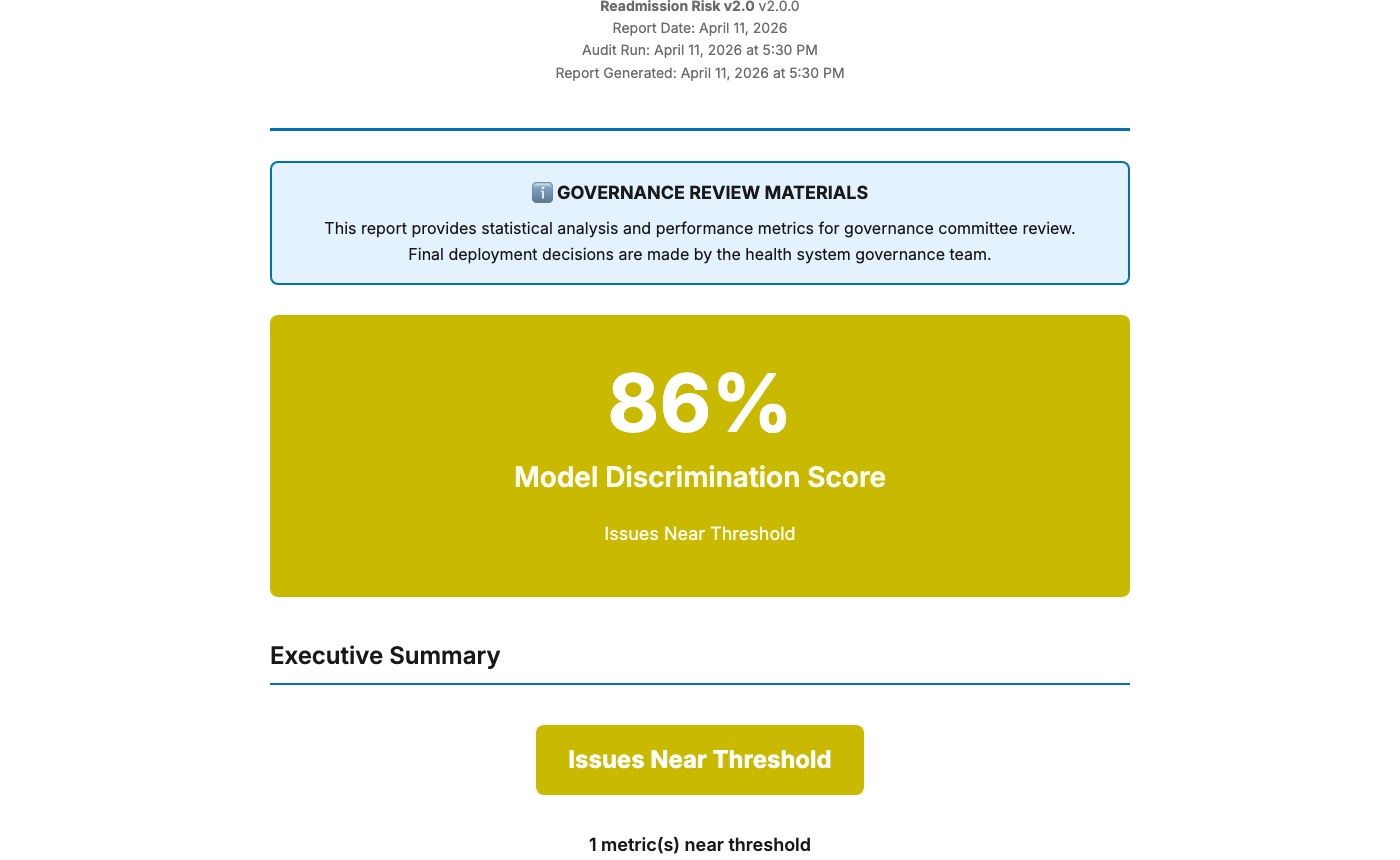
Executive summary — traffic-light deployment status at a glance
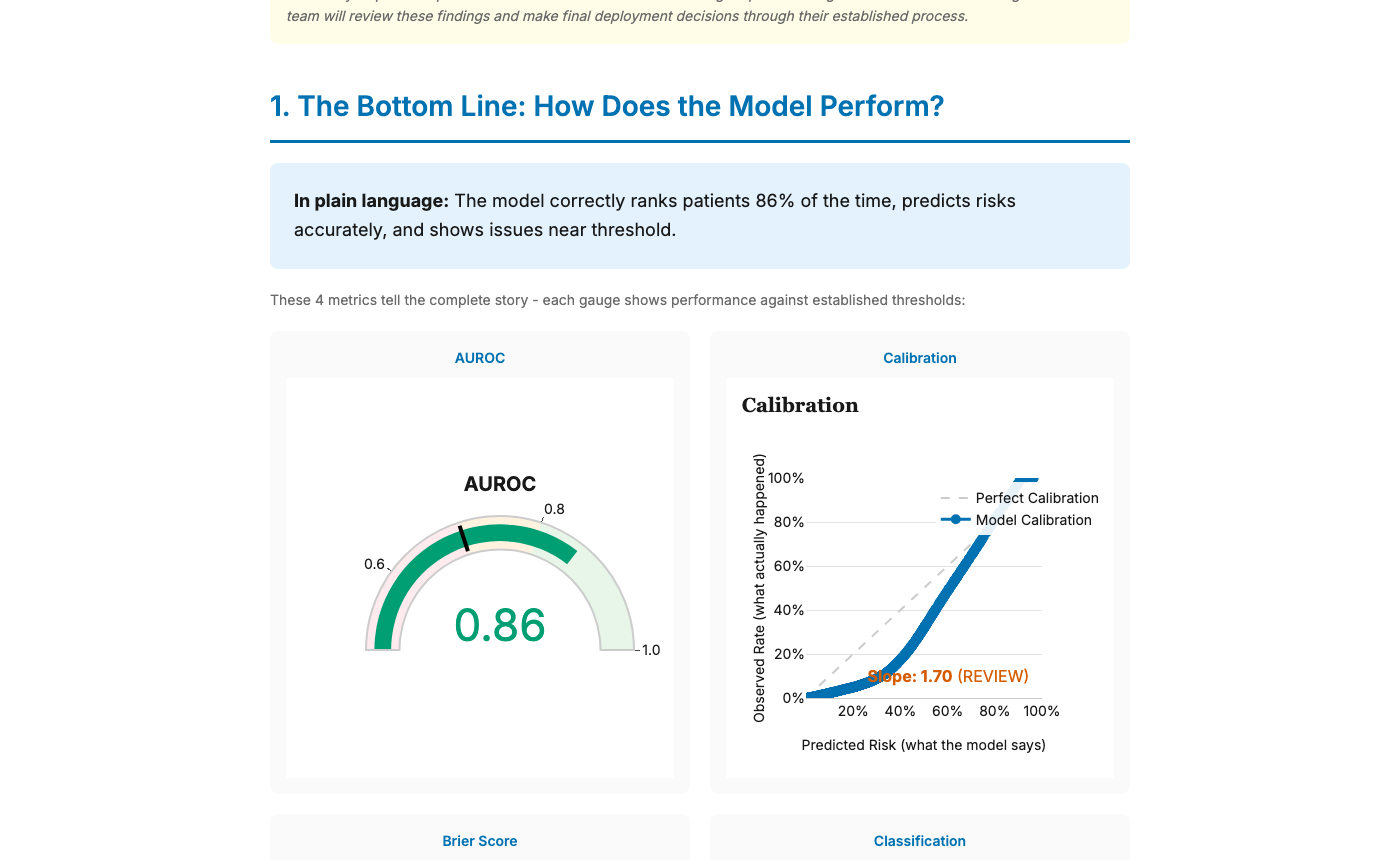
Performance metrics with plain-language explanations for non-technical reviewers
Generated from synthetic ICU data using pip install faircare
Who It's For
Built for healthcare AI teams
From clinical model development through governance sign-off.
Hospital Data Scientists
Full 15–20 page technical reports: AUROC, calibration, DCA, bootstrap confidence intervals, all subgroup figures. Export as HTML, PDF, or PNG bundles. Auto-detected sensitive attributes.
Clinical Informaticists
Governance-ready reports with plain-language explanations suitable for IRB, ethics committees, or C-suite review. Pass/warning/flag indicators at a glance.
Governance Committees
3–5 page summaries with 8 key figures, clear pass/warning/flag indicators, sign-off workflows, and audit trail documentation. Readable without a statistics background.
Health Equity Researchers
Publication-ready figures — WCAG 2.1 AA, colorblind-safe Okabe-Ito palette, 14px minimum — with full methodology citations.
Regulatory & Compliance Teams
Structured model cards, responsible AI checklists, XML compliance validation, and reproducibility bundles. Everything needed for regulatory submission or internal audit trails.
Built for clinical AI governance & reporting standards
Funding & Acknowledgement
This project was supported by the Institute for Translational Medicine (ITM) at the University of Chicago and Rush University, funded by the National Center for Advancing Translational Sciences (NCATS) of the National Institutes of Health (NIH) through Grant Number UL1TR002389 (Clinical and Translational Science Award).
The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
Developed and maintained by RICCC Lab · J.C. Rojas, MD, MS